
TiDAR: Think in Diffusion, Talk in Autoregression (Paper Analysis) – nvidia
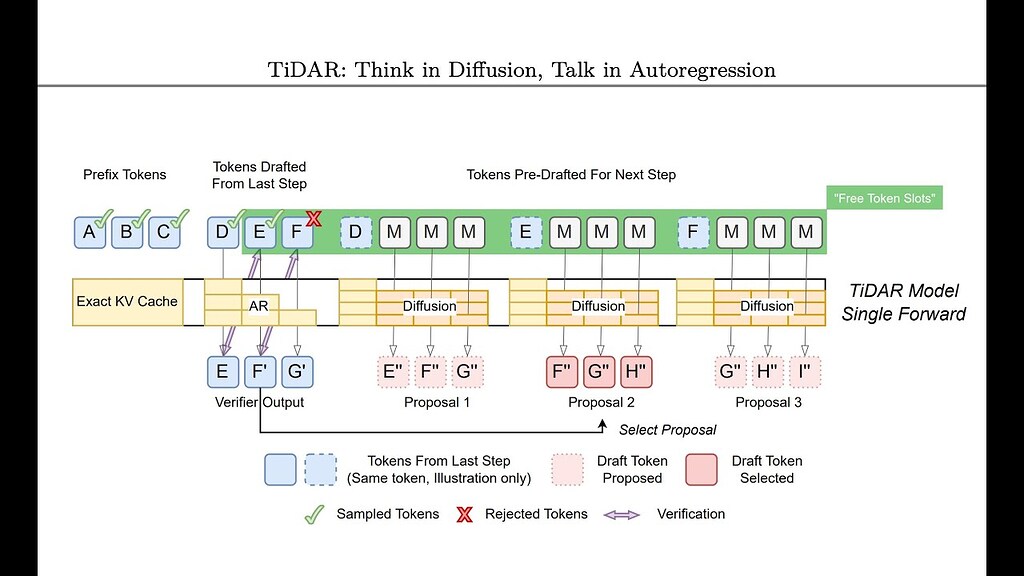
The video analyzes the TiDAR paper, “Think in Diffusion, Talk in Autoregression,” by NVIDIA researchers. The core idea is that during large language model (LLM) inference, GPUs are often underutilized due to memory bottlenecks. TiDAR proposes a method to exploit this unused GPU capacity to accelerate inference without sacrificing the quality of output, unlike previous […]
TiDAR: Think in Diffusion, Talk in Autoregression (Paper Analysis)
TiDAR: Think in Diffusion, Talk in Autoregression (Paper Analysis) Source link