
Are AI Benchmarks Telling The Full Story? [SPONSORED] – benchmarking

The video discusses the limitations of current AI benchmarks and the importance of incorporating human-centered evaluations to better understand how AI models perform in real-world scenarios. The speakers compare AI models to Formula 1 cars, which are engineering marvels but impractical for daily use, suggesting that models excelling in technical benchmarks like MMLU (Humanity’s Last […]
GPT-5.2 is dumb (I’m tired of benchmarks) – benchmarking
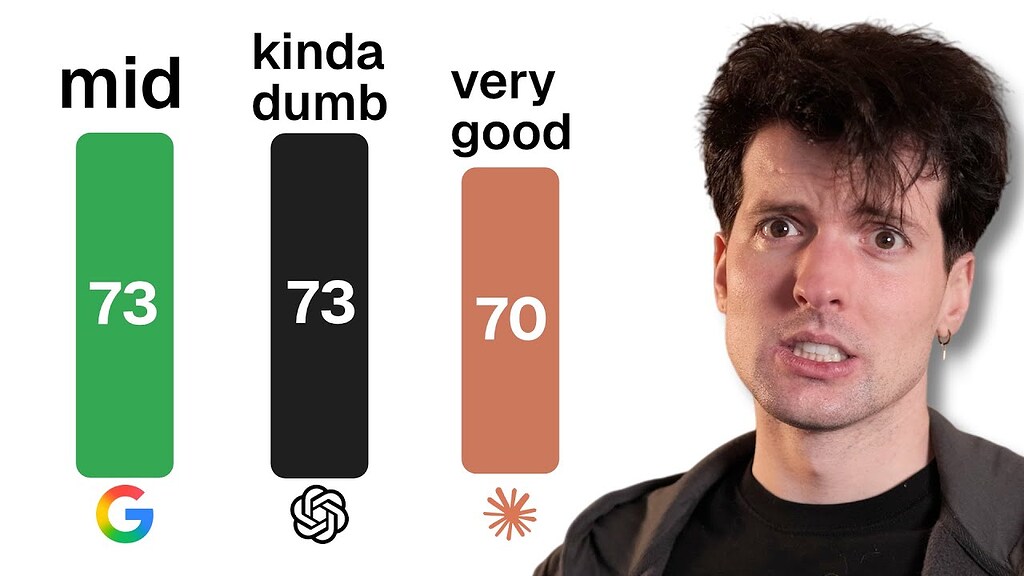
The video discusses the recent release of GPT-5.2, highlighting both its impressive benchmark performance and its notable shortcomings. The creator points out some bizarre errors made by the model, such as incorrectly counting letters in words and making illogical financial comparisons. Despite these issues, the model excels in traditional benchmarks, especially in high-level research tasks […]
GPT-5.2 is the best model ever made – benchmarking

The video provides an in-depth review of the newly released GPT-5.2 model, highlighting both its impressive advancements and notable regressions. While GPT-5.2 excels in code generation, tool calls, and benchmarks like ARC AGI, it surprisingly shows a significant regression in three-dimensional spatial reasoning, as demonstrated by its poor performance on a skateboard trick naming benchmark. […]
DeepSeek V3.2 Just Broke SoTA Again… But How? – benchmarking

The release of DeepSeek V3.2 has generated significant excitement in the AI community, as it has surpassed OpenAI’s flagship GPT-5 High model and is comparable to Google’s Gemini 3 Pro, all while being remarkably cost-effective. DeepSeek V3.2 is touted as the cheapest frontier AI model available, costing about ten times less than other state-of-the-art models. […]